1. shellcode简介
shellcode是一段用于利用软件漏洞的有效载荷(payload),它通常是16进制的机器码,以其经常让攻击者获得shell而得名。shellcode通常使用机器语言编写,因此无需编译,可以直接在CPU上执行。
1.1 shellcode特点
- 紧凑高效:shellcode代码非常简短,以方便在有限的内存区域注入并执行;
- 自主运行:shellcode通常包含了所有代码和相关数据(使用系统调用实现),且不依赖于其他的资源,就可以在目标系统独立运行;
- 直接运行:shellcode通常是二进制机器码,无需编译即可在CPU直接执行;
- 位置无关:shellcode通常被设计成位置无关代码,这意味着它们不依赖于固定的内存地址,可以在内存中的任何位置执行;
- 避免“坏字符”:shellcode通常会避免包含某些特定字符,以防止字符被截断;
1.2 shellcode获取方式
- 直接在网上搜索下载shellcode代码;
- 通过工具生成相应的shellcode代码,比如CS、MSF等工具;
- 自己手工编写shellcode,可使用机器码、汇编语言、C/C++语言编写;
前两种就不说了,工具生成很简单,网上搜一下教程即可,这里主要使用汇编语言手工编写shellcode。
1.3 shellcode编写规则
shellcode的功能虽然强大,但也会像编写应用程序那样,有多种编写规则:
- 不能使用绝对地址(全局变量):全局变量被编译加载后,内存地址通常是固定的,操作系统加载器会把引用全局变量的代码链接到这个地址上,这是一个正常的流程;然而shellcode并不是exe文件,不需要操作系统去加载,而是被注入到正在运行的进程内存空间中,即被注入的地址是随机的、变化的,因此shellcode的操作都应该是相对的;
- 不能使用调用系统函数:函数地址的不确定性,由于ASLR机制,DLL每次加载的地址都不一样,所以不能依赖于DLL的偏移量,而是要通过PEB结构等相关操作查找函数地址;
- 避免坏字符:NULL字节是字符串的终止符,shellcode中这些字节的存在会干扰核心功能;
- 极简模式:保证shellcode功能完善的前提下,应该尽量减小体积,更容易被注入和编码,比如这里要写的Stage分段shellcode通常只有几十个byte大小,然后在内存中下载并组装更大的、被加密编码的第二阶段载荷,以此绕过安全防御;
2. 环境搭建
工欲善其事,必先利其器。想要写出好的程序,首先得需要强大的工具,编写shellcode需要用到的工具:
- Visual Studio 2017:微软公司研发的一款功能强大的集成开发环境(IDE);
- 010 Editor:功能强大、支持多种模式的十六进制编辑器;
- WIndows10虚拟机环境:编写后的shellcode放到虚拟机中执行,物理机可能会被杀软干掉;
- shellcode加载器:用于将shellcode加载到内存并执行,比如pe_to_shellcode工具,或者自己编写一个加载器也可以实现该功能;
Visual Studio 2017环境设置
编写shellcode之前,需要先进行环境设置,首先打开Visual Studio 2017:
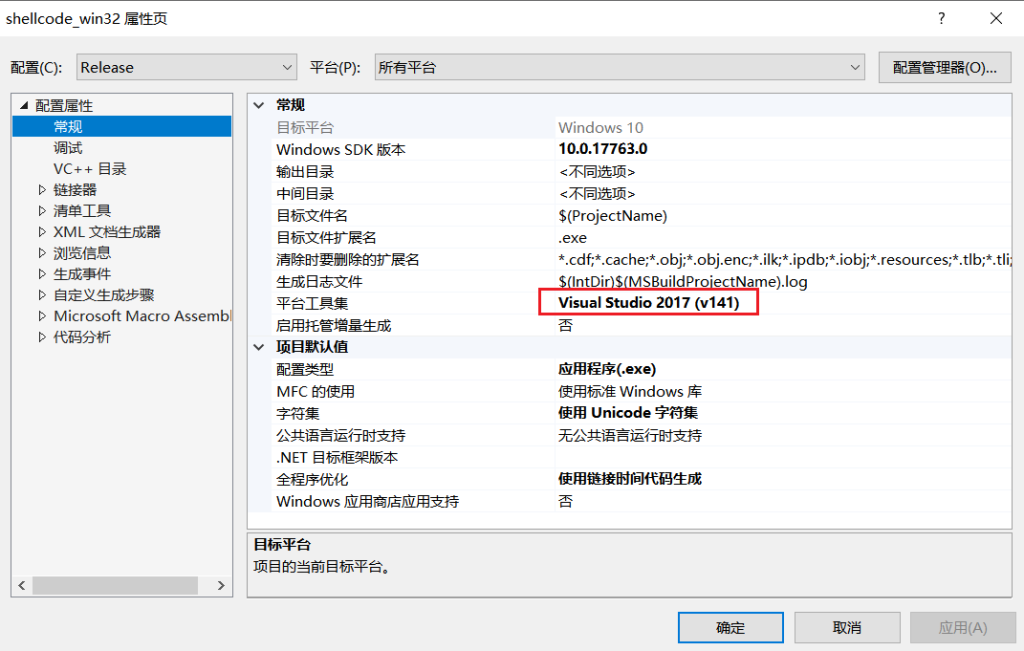
第一步:查看平台工具集:菜单栏-项目-属性,默认的工具集是Visual Studio2017+ml32+link,64位下就是ml64,也就是masm汇编器+link链接器集一体的,IDE都准备好了,直接写代码就可以了:
第二步:创建一个控制台应用:
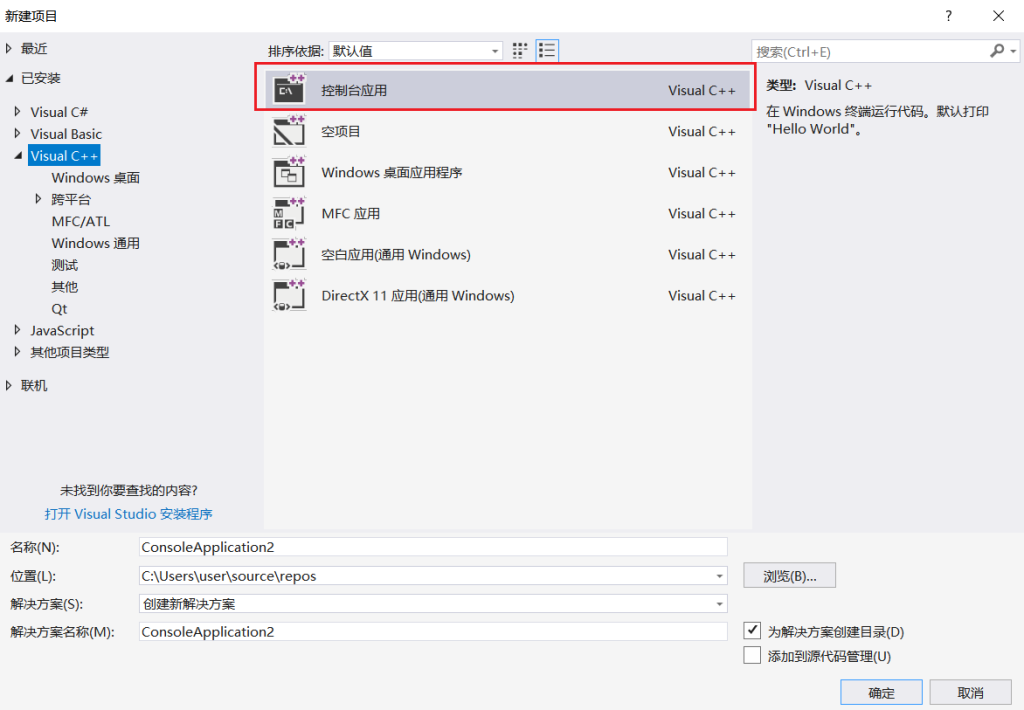
创建成功以后,就会发现有一个带有main函数的cpp文件,没有什么用处,把它删掉即可;
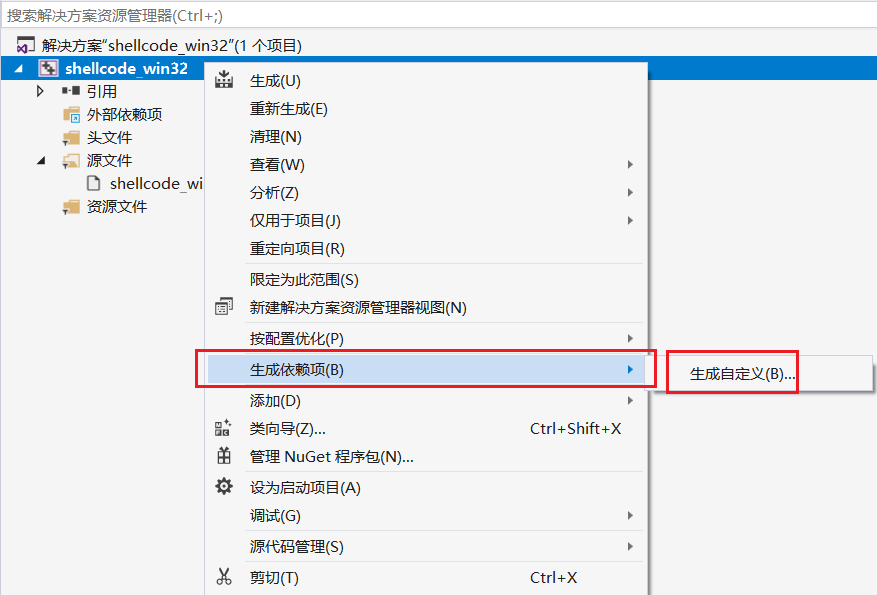
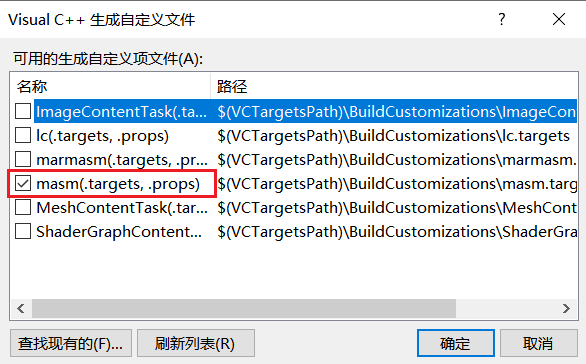
第三步:接下来为项目配置环境:右键项目-生成依赖项-生成自定义,选择masm选项,点击确定:
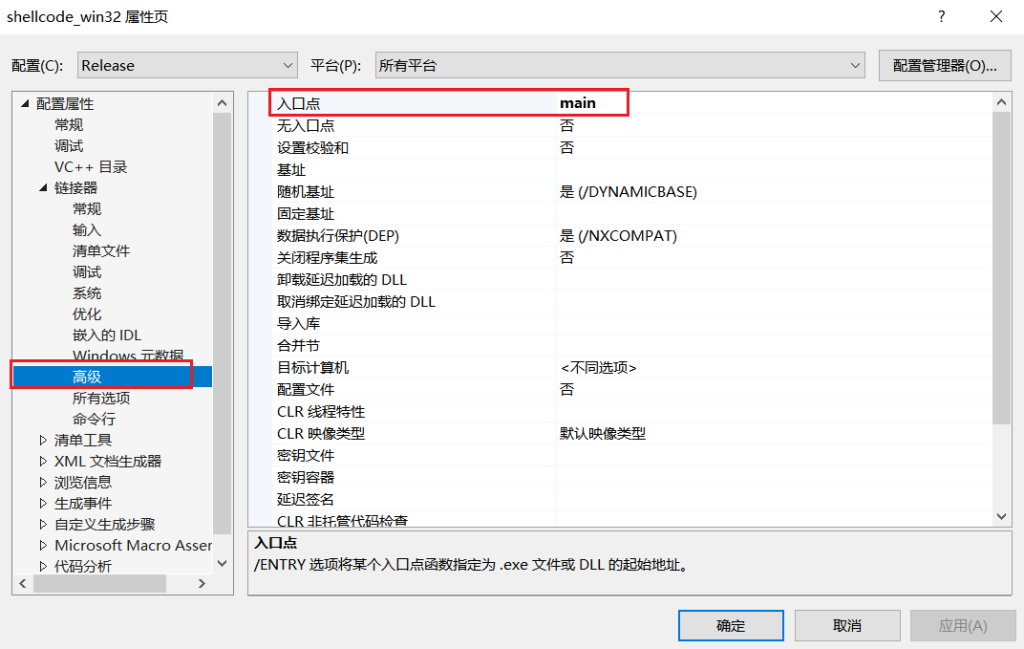
第四步:设置程序的入口点main:右键项目-高级-入口点,Debug和Release模式都要设置:
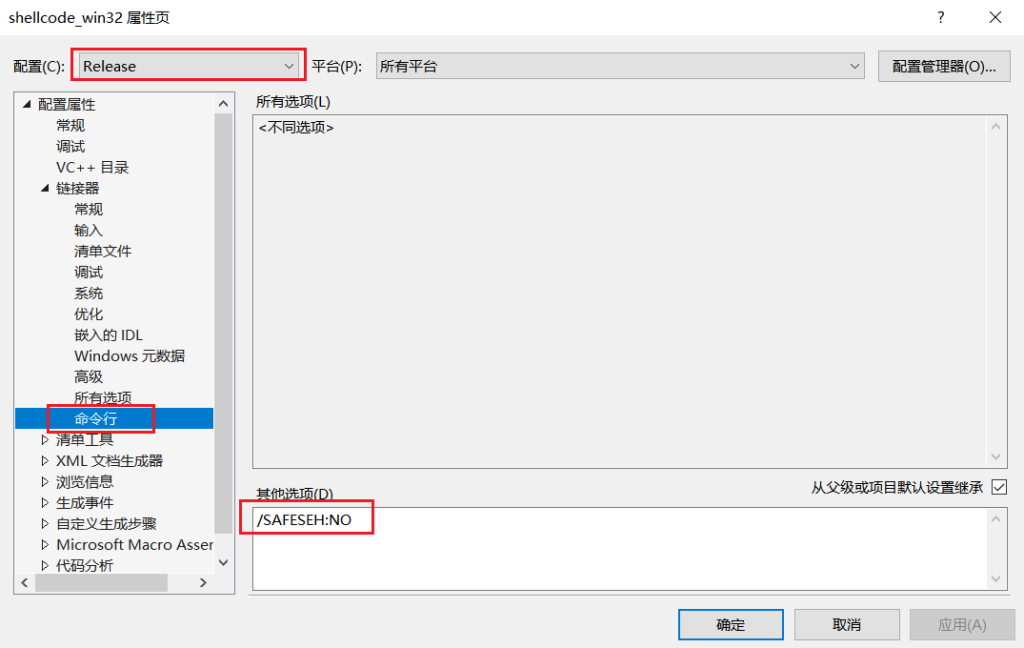
第五步:命令行中Release设置/SAFESEH:NO,用于关闭SEH保护机制,确保程序可以正确链接:
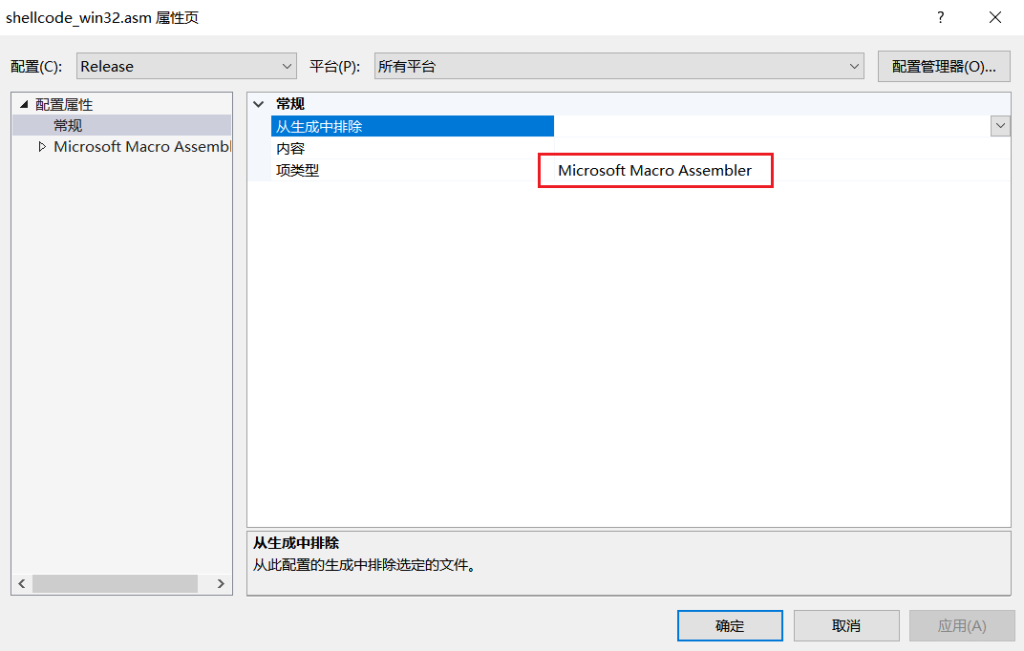
第六步:新建一个asm汇编文件,右键查看文件属性,确定是Microsoft Macro Assembler类型:
到了这里,环境配置基本就完成了,然后在asm汇编里写代码就可以了。
3. shellcode(32位弹窗)
我们先来编写32位的shellcode,代码参考MSF框架的shellcode源码:
- block_api.asm:shellcode实现的核心文件,几乎所有的功能实现都引用了这个文件,主要功能是动态解析Hash值来查找相应的函数地址:metasploit–block_api.asm;
- x86/src/block:实现具体功能的shellcode,比如http方式实现远程shellcode等;
- x86/src/stager:该目录下包含了shellcode的最终功能实现:metasploit/stager;
我们大部分的代码将引用自MSF框架,只做小部分的改动,逐步进行代码分析。
shellcode源码包下载:https://github.com/peiqi0818/shellcode-list
总体上来说该程序是由一个main主程序和一个获取函数地址的子程序组成的,先看子程序的实现:
3.1 get_proc_addr_by_hash子程序
(1)第一步,保存寄存器和hash到栈
pushad ;8个寄存器入栈,esp-32
mov ebp,esp ;开辟一个新栈帧
mov eax,[esp+0x24] ;保存哈希值到当前栈中,保存
push eax ;第一次压栈,存储hash值[ebp-4]指令分析
- pushad:全称为Push All Double(压入所有双字),堆栈指针寄存器ESP会自动减去32个字节,然后将8个32位通用寄存器的内容按特定顺序一次性压入32位堆栈中,压栈的特定顺序:EDI-ESI-EBP-ESP(初始值)-EBX-EDX-ECX-EAX;
- mov ebp,esp:将ebp基址设定为当前的esp的值,即开辟一个新的栈帧;
- mov eax,[esp+0x24]:保存哈希值到栈上;
- push eax:相当于将目标哈希值存到了新开辟的栈帧中;
(2)第二步,从PEB结构获取
xor edx, edx ;对edx寄存器做清零操作
assume fs:nothing ;忽略段寄存器的默认假设
mov edx, [fs:edx+0x30] ;获取PEB地址
mov edx, [edx+0xc] ;定位到_PEB_LDR_DATA结构体
mov edx, [edx+0x14] ;定位到第一个模块节点指令分析
- xor edx, edx:异或运算,作用是将edx寄存器清零,简洁高效还避免坏字符;
- assume fs:nothing:忽略段寄存器的默认假设,否则读取不了fs寄存器;
- mov edx, [fs:edx+0x30]:之前的帖子说了fs寄存器指向了TEB,那么偏移0x30的位置就存放了PEB结构体指针,当前的edx寄存器指向了_PEB结构体;
- mov edx, [edx+0xc]:PEB结构体的偏移0xc位置处存放了_PEB_LDR_DATA结构体指针,当前的edx寄存器指向了_PEB_LDR_DATA结构体;
- mov edx, [edx+0x14]:_PEB_LDR_DATA结构体偏移0x14位置处存放了InMemoryOrderModuleList模块链表的指针,当前的edx寄存器指向了InMemoryOrderModuleList模块链表;
重点说明一下:InMemoryOrderModuleList模块链表是一个_LIST_ENTRY双向循环链表结构,此时edx指向的是头结点,也就是进程本身。
(3)第三步:模块遍历
next_mod: ;标号
mov esi, [edx+0x28] ;获取模块名称
movzx ecx, word [edx+0x26] ;获取名称长度
xor edi, edi ;edi寄存器清零,用于存储模块名称的哈希值_LIST_ENTRY是一个“嵌入式”双向循环结构,也就是说该结构不存储任何成员,通常被嵌入到一个大型的数据结构中使用,即需要指向实际的数据节点,所以说_LIST_ENTRY结构实际的数据节点是_LDR_DATA_TABLE_ENTRY结构体,更详细的描述请参考:PEB结构体族
指令分析
看一下这四个结构体之间的关系,就可以明白该指令的作用。_LIST_ENTRY的结构体:
//0x30
struct _PEB_LDR_DATA
{
ULONG Length; //0x0
UCHAR Initialized; //0x4
VOID* SsHandle; //0x8
struct _LIST_ENTRY InLoadOrderModuleList; //0xc
struct _LIST_ENTRY InMemoryOrderModuleList; //0x14
struct _LIST_ENTRY InInitializationOrderModuleList; //0x1c
VOID* EntryInProgress; //0x24
UCHAR ShutdownInProgress; //0x28
VOID* ShutdownThreadId; //0x2c
}; 可以看到这三个模块链表都是_LIST_ENTRY结构,定义如下:
//32位0x08
struct _LIST_ENTRY
{
struct _LIST_ENTRY* Flink; //0x00:指向链表中下一个元素的_LIST_ENTRY部分
struct _LIST_ENTRY* Blink; //0x04:指向链表中上一个元素的_LIST_ENTRY部分
};注意了,这里的Flink和Blink指向的不是_LDR_DATA_TABLE_ENTRY结构的起始地址,而是指向下一个_LDR_DATA_TABLE_ENTRY结构体内部的InMemoryOrderLinks成员的地址(0x08)。
_LDR_DATA_TABLE_ENTRY结构体定义如下:
struct _LDR_DATA_TABLE_ENTRY
{
struct _LIST_ENTRY InLoadOrderLinks; //0x0
struct _LIST_ENTRY InMemoryOrderLinks; //0x8
struct _LIST_ENTRY InInitializationOrderLinks; //0x10
VOID* DllBase; //0x18
VOID* EntryPoint; //0x1c
ULONG SizeOfImage; //0x20
struct _UNICODE_STRING FullDllName; //0x24
struct _UNICODE_STRING BaseDllName; //0x2c
...
...
}movzx ecx, word ptr [edx+0x24]:这条指令的作用是获取模块(DLL)的长度,就是获取到BaseDllName这个成员,它是一个_UNICODE_STRING结构体,第一个元素就是长度,此时的edx寄存器指向了0x08位置,所以0x2c-0x8=0x24;
_UNICODE_STRING结构体定义如下:
struct _UNICODE_STRING
{
USHORT Length; //0x0
USHORT MaximumLength; //0x2
WCHAR* Buffer; //0x4
}; 该结构的第三个成员才是存储实际的字符串数据,即DLL名称的所在地,所以0x8偏移0x24到BaseDllName成员,然后再偏移0x4就可以获取到DLL的名称了。
(4)第四步,计算目标模块hash值
loop_modname: ;
xor eax, eax ; 清零eax=0
lodsb ; 读取名称的下一个字节,从esi加载一个字节到al,esi自动递增
cmp al, 'a' ; 检查名称是否为小写字母(ASCII 97)
jl not_lowercase ; 如果是小写字母则跳转到not_lowercase
sub al, 0x20 ; 将小写字母转换为大写
not_lowercase: ; 标号
ror edi, 0xd ; 将edi循环右移13位(哈希值混合高低位)
add edi, eax ; 添加名称的下一个字节,将字符值累加到edi(哈希值更新)
dec ecx ; 字符计数器ecx减1
jnz loop_modname ; 判断ecx的值,若未处理完所有字符,则继续循环
push edx ; 将当前模块链表节点地址压栈,位于[ebp-8]
push edi ; 将计算完成的哈希值压栈存储hash值,位于[ebp-12] 这一步主要是计算哈希值的生成方式,关键指令分析:
- lodsb:该指令是字符串操作指令,用于从内存中读取一个字节到al寄存器,esi寄存器将自动递增,在这里主要用于后面的大小写字符转换;
- cmp al, ‘a’:比较al寄存器与字母a的ASCII值(97)的大小,如果al寄存器的值小于a,说明不是小写字母,则直接跳转到not_lowercase标号处执行,如果al寄存器的值大于a,说明是小写字母,则不执行跳转操作,执行后面的sub al, 0x20,手动将小写字母转换为大写;
- ror edi, 0xd:哈希算法实现的核心指令,将edi寄存器中的值向右循环右移13位,ror指令同shr右移不同,ror指令会将从最低有效位移出的位重新填充到最高有效位,shr右移会将溢出的位舍弃改用0填充,当然这里的位数可以改成其他数字;
- add edi, eax:将字符值累加到edi寄存器中,下一次还会进行ror指令计算;
- dec ecx:控制字符的计数,每次执行完ecx寄存器的值减1;
- push edx:此时的edx寄存器还指向当前的模块节点,所以这里将模块节点地址压栈;
(5)第五步,获取导出表
mov edx, [edx+0x10] ;获取模块的基址(即映像基址,DllBase)
mov eax, [edx+0x3c] ;获取PE头RVA
add eax, edx ;RVA转VA,获取PE头地址
mov eax, [eax+0x78] ;获取导出表的RVA
test eax, eax ;检测eax寄存器是否为空
jz get_next_mod1 ;获取下一个模块
add eax, edx ;RVA转VA,获取导出表的地址
push eax ;存储导出表的地址到栈上(ebp-16位置处)
mov ecx, [eax+0x18] ;获取按名称导出的函数总数
mov ebx, [eax+0x20] ;获取函数名称字符串地址数组的RVA
add ebx, edx ;RVA转VA,获取函数名称字符串地址数组的VA具体指令分析
- mov edx, [edx+0x10]:此时的edx指向了
InMemoryOrderLinks(0x08),所以再偏移0x10获取DllBase模块基址,即就是模块被加载到内存的映像基址,由此就进入了PE文件格式的操作; - mov eax, [edx+0x3c]:此时的edx指向了模块基址(DOS头),偏移0x3c获取e_lfanew成员,该成员指向了PE头;
- add eax, edx:获取PE头的地址,然后将其存放到eax寄存器;
- mov eax, [eax+0x78]:
- mov eax, [eax+0x78]:此时的eax指向了PE头,_IMAGE_OPTIONAL_HEADER结构体偏移0x78即可定位到DataDirectory成员,该 成员的第一项就是导出表结构;
- test eax, eax:检测eax寄存器是否为0,主要用于判断条件是否执行转移操作;
- jz get_next_mod1:当eax为0时,跳转到get_next_mod1模块执行,继续获取下一个模块;
- add eax, edx:获取导出表的地址,存到eax寄存器;
- push eax:保存当前导出表的地址到栈上;
- mov ecx, [eax+0x18]:此时的eax指向了导出表结构的基址,偏移0x18获取NumberOfNames成员,即以名称导出函数的总数;
- mov ebx, [eax+0x20]:导出表结构偏移0x20获取AddressOfNames成员,即函数名称字符串地址数组的RVA,存到ebx寄存器;
- add ebx, edx:通过基址加上RVA得到函数名称字符串地址数组的VA;
(6)第六步,获取API函数名称
get_next_func:
test ecx, ecx ; 检测按名称导出的函数数量是否为0
jz get_next_mod ; 如果为0,跳转到下一个模块
dec ecx ; 函数计数器ecx减1(倒序遍历)
mov esi, [ebx+ecx*4] ; 从后往前遍历,一个函数名RVA占4字节
add esi,edx ; 映像基址与函数名组合
xor edi,edi ; edi清零,用于后面存储函数hash值这一步的功能是通过循环遍历模块获取函数的名称,关键指令解析:
- test ecx, ecx:当前ecx存储的是导出的函数总数,这里是用于循环获取函数的名称判断,每执行完一次循环,ecx寄存器的值就减1,当ecx为0时,则跳转到下一个模块;
- mov esi, [ebx+ecx*4]:该指令用于遍历函数名称,此时ebx指向字符串地址数组,ecx指向导出函数的数量(索引),4表示每个函数名占4个字节,将遍历的结果存到esi寄存器;
- add esi,edx:此时edx指向PE文件的映像基址,与esi中的函数名相加存到esi寄存器
(7)第七步:计算模块hash+函数hash之和
loop_funcname:
xor eax, eax ; eax清零
lodsb ; 加载字符到al,esi++
ror edi, 0x0d ; 哈希值循环右移13位
add edi, eax ; 累加字符ASCII值到哈希
cmp al, ah ; 检测是否到达字符串的终止符 \0(ASCII 0)
jne loop_funcname ; 未到结尾则继续循环
add edi,[ebp-12] ; 加上之前的模块hash
cmp edi,[ebp-4] ; 与目标hash进行比较
jnz get_next_func这一步的功能是计算模块哈希与函数哈希的和,关键指令分析:
- cmp al, ah:该指令用于比较al和ah的值,结合上下文,al存储加载的字符,如果还没有到达字符串的末尾则执行jne loop_funcname继续循环,如果到达字符串的结尾\0,则与ah的值相同,表示字符串读取完成且进行了哈希算法计算;
- add edi,[ebp-12]:之前的函数名hash已经计算完成,则将之前压栈的模块hash与现在计算的函数名hash进行相加得到最终的hash值;
- cmp edi,[ebp-4]:将计算出的模块hash与函数hash相加得到的最终结果与目标hash值进行比较,如果结果为0,则表示hash值相同,找到了该函数,否则执行jnz get_next_func处的代码;
(8)第八步:获取目标函数指针
get_funcAddress:
pop eax ;从栈中读取之前存放的当前模块的导出表地址
mov ebx, [eax+0x24] ; 获取序号表(AddressOfNameOrdinals)的 RVA
add ebx, edx ;RVA转VA,序号表起始地址
mov cx, [ebx+2*ecx] ; 从序号表中获取目标函数的导出索引
mov ebx, [eax+0x1c] ; 获取函数地址表(AddressOfFunctions)的 RVA
add ebx, edx ; RVA转VA,AddressOfFunctions数组的首地址
mov eax, [ebx+4*ecx] ; 获取目标函数指针的RVA
add eax, edx ; RVA转VA,获取目标函数指针的地址哈希值比较正确后就来到了这一步,这一步的功能就是获取函数的地址,具体方式:将之前第五步保存的导出表地址弹出来,偏移0x24获取AddressOfNameOrdinals的RVA,然后加上基址得到VA;接着获取目标函数的导出索引,然后又是一系列的RVA和VA的转换操作,最终得到了目标函数指针的地址。
(9)第九步:清栈恢复现场,调用目标函数
finish:
pop ebx ; 清除之前的模块+函数的hash值
pop ebx ; 清除当前模块链表的位置
pop ebx ; 清除目标hash值
mov [esp+28],eax ; 将API函数地址保存eax中
popad ; 恢复之前压入的8个通用寄存器
pop ecx ; 弹出调用者压入的原始返回地址(由 CALL 指令保存的)
pop edx ; 弹出调用者压入的哈希值
push ecx ; 保存原始返回地址,与jmp eax模拟call指令
jmp eax ; 跳转到目标 API 函数地址这一步的功能是恢复栈现场,然后将函数的地址保存到eax寄存器跳转。
3.2 main函数
main函数是该程序运行的起点,负责启动程序、控制程序流程等一系列操作。
main函数代码如下:
main:
push 00006c6ch ; 将字符串"ll"压栈
push 642e3233h ; 将字符串"d.23"压栈
push 72657375h ; 将字符串"user"压栈
push esp ; esp寄存器始终指向栈顶,所以这里是将字符串的地址压栈
push 0DEC21CCDh ; 计算出的kernel32.dll+LoadLibraryA函数的哈希值
call get_func_address ; 调用哈希解析函数获取LoadLibraryA地址,加载user32.dll
xor ebx,ebx ; 清零ebx,用于后续存储参数
push ebx ; uType=0
push ebx ; lpCaption=NULL
push ebx ; lpText=NULL
push ebx ; hWnd=NULL
push 0x790E24F0 ; 计算出user32.dll+MessageBoxA函数的哈希值
call get_func_address ; 调用MessageBoxA函数,返回值在eax
push eax ; uExitCode参数,若为0,表示成功退出
push 0x2E3E5B71 ; 计算出kernel32.dll+ExitProcess函数的哈希值
call get_func_address ; 调用ExitProcess函数退出main函数的主要功能是:
- 通过调用get_proc_addr_by_hash函数获取LoadLibraryA函数地址,加载user32.dll库文件;
- 调用MessageBoxA函数,返回值存在eax寄存器(默认);
- 调用ExitProcess函数退出程序;
3.3 shellcode运行测试
shellcode编写好之后,选择Release-X86模式,右键项目-生成,就会生成一个exe的可执行文件:
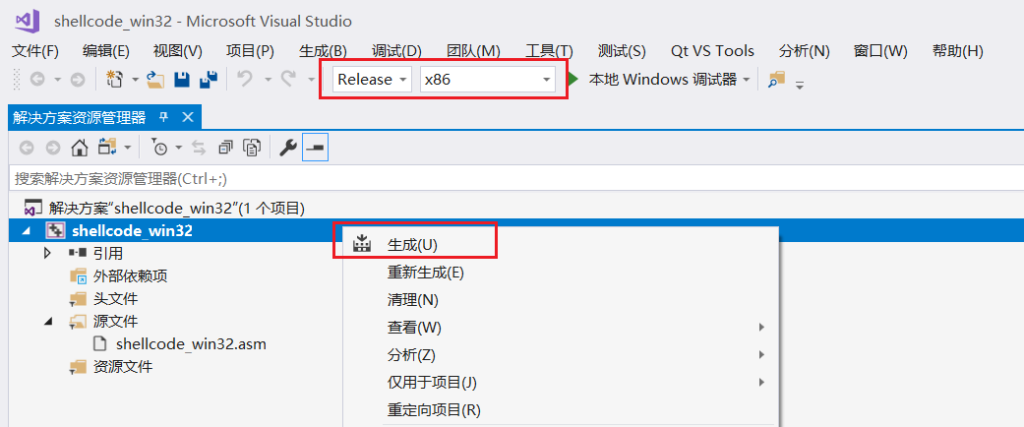
生成exe可执行文件后直接运行即可:
也可以打开010 Editor编辑器,文件-打开-刚刚生成的exe文件,选择.text节:

右键选择.text节-选择-保存选择为bin二进制文件:
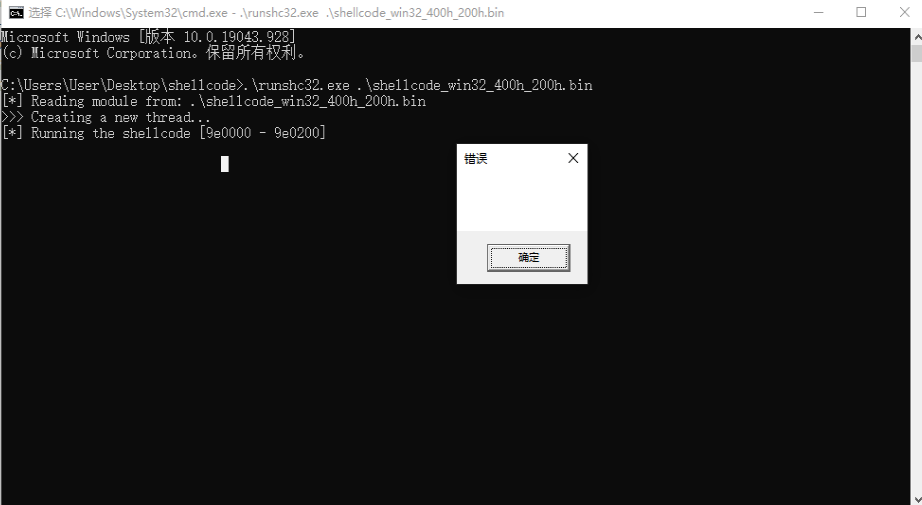
shellcode代码不能直接运行,而是要通过加载器来进行注入执行。推荐使用pe_to_shellcode加载器,找对应的runshc32.exe运行即可。
注意:使用加载器之前需要将杀软关闭,否则会被杀掉。
4. shellcode(64位弹窗)
64位的环境配置与32位的基本一致,这里不再多说了。
代码参考也是根据msf的x64-shellcode,这里也不再多说了,和32位类似。
shellcode源码包下载:https://github.com/peiqi0818/shellcode-list
64位的shellcode与32位的思路基本是一致的,区别主要如下:
- 对齐规则:x86-64架构的ABI规定,调用函数之前,RSP寄存器要求16字节对齐;
- 寄存器传参:X86架构依赖栈传参,X64架构优先使用寄存器传参,剩余参数放入栈中;
- 偏移量不同:PE文件格式及PEB等结构体成员大小比32位有了明显的扩展,所以汇编指令获取成员的偏移量也会有所不同;
- 寄存器扩展:X64架构支持16个通用寄存器,所以有些地方不再依赖于堆栈。
4.1 get_proc_addr_by_hash子程序
该子程序同32位的功能一致,只是汇编指令不同。
(1)第一步,将前4个参数及rsi寄存器压栈
push r9 ;第4个参数
push r8 ;第3个参数
push rdx ;第2个参数
push rcx ;第1个参数
push rsi ;保存rsi寄存器到栈根据Windows X64调用约定规则;将使用__fastcall机制,优先使用寄存器进行参数传递。前4个参数依次通过rcx、rdx、r8、r9寄存器传递;rsi寄存器被定义为“由调用者保存的寄存器”,后续对rsi寄存器使用容易破坏原始值,所以需要压栈保存。
(2)第二步,从 PEB 结构获取
InMemoryOrderModuleList 模块链表的第一个节点:
xor rdx,rdx ;清零rdx
mov rdx,gs:[rdx+0x60] ;通过GS段寄存器获取PEB地址
mov rdx,[rdx+0x18] ;定位到_PEB_LDR_DATA结构体
mov rdx,[rdx+0x20] ;定位到第一个模块节点(链表InMemoryOrderModuleList的基址)X64架构下,GS寄存器指向了TEB,TEB偏移0x60位置处存放了PEB的地址,进入PEB结构体再偏移0x18找到_PEB_LDR_DATA结构体,再偏移0x20,定位到InMemoryOrderModuleList的基址,这里的步骤和32位的一样,就是偏移量不一致而已。
(3)第三步:模块遍历
next_mod: ;标号
mov rsi, [rdx+0x50] ;获取模块名称
movzx rcx, word [rdx+0x4a] ;获取模块名称长度,此时的rdx指向InMemoryOrderLinks成员
xor r8,r8 ;r8寄存器清零,用于存储模块名称的哈希值这里的功能同32位,只是偏移量不一样,不再多说了,r9寄存器用于存储模块名称的哈希值。
(4)第四步:计算目标模块 hash 值
loop_modname:
xor rax, rax ;清零rax,准备处理字符
lodsb ;读取名称的下一个字节,自动递增rsi
cmp al,'a' ;比较当前字符的ASCII值,是否为小写字母
jl not_lowercase ;如果小于a,则不是小写字母,则跳转
sub al, 0x20 ;将a-z小写字母转换为大写A-Z
not_lowercase:
ror r8d,0dh ;对R8的低32位进行循环右移13位,且不影响高32位
add r8d,eax ;添加名称的下一个字节,将当前字符的ASCII值累加到哈希值
dec ecx ;字符计数器rcx减1
jnz loop_modname ;继续循环处理下一个字符,直到rcx减至0
push rdx ;将当前模块链表节点地址压栈
push r8 ;将计算完成的哈希值压栈存储hash值这是一步是hash值的计算方式,同32位一致,只是寄存器不一致,不再多说了。
(5)第五步:获取导出表
mov rdx, [rdx+20h] ;获取模块基址,字段DllBase
mov eax, dword ptr [rdx+3ch] ;读取PE头的RVA
add rax, rdx ;RVA转换为VA
cmp word ptr [rax+18h],20Bh ;检测是否为PE32+文件
jne get_next_mod1 ;如果不是就下一个模块
mov eax, dword ptr [rax+88h] ;获取导出表的RVA
test rax, rax ;检测该模块是否有导出函数
jz get_next_mod1 ;如果没有就下一个模块
add rax, rdx ;RVA转为VA
push rax ;存储导出表的地址压栈
mov ecx, dword ptr [rax+18h] ;按名称导出的函数总数
mov r9d, dword ptr [rax+20h] ;函数名称字符串地址数组的RVA
add r9, rdx ;RVA转为VA还是一如既往的计算偏移量得到RVA,通过模块基址加上RVA得到VA,还有就是64位的寄存器多了,我们可以更灵活的使用,有一点需要说明,这里的dword ptr是内存地址修饰符,表示读取4个字节的数据存到32位的寄存器。其他地方同32位的步骤一样,只是偏移量不同,不再多说了。
还有一点就是cmp word ptr [rax+18h],20Bh指令用于判断32位还是64位的PE文件,增加了进一步检测。
(6)第六步:获取 API 函数名称
get_next_func:
test rcx, rcx ; 检测按名称导出的函数数量是否为0
jz get_next_mod ; 若所有函数已处理完,跳转至下一个模块遍历
dec rcx ; rcx递减(从后向前遍历函数名数组)
mov esi, dword ptr [r9+rcx*4] ; 从后往前遍历,一个函数名RVA占4字节
add rsi, rdx ; 函数名RVA
xor r8, r8 ; r8寄存器清零,用于存储后面的函数名哈希这里也是同32位一致的步骤,不再多说了。
(7)第七步:计算模块 hash + 函数 hash 之和
loop_funcname:
xor rax, rax ; 清零eax
lodsb ; 从rsi加载一个字节到al,rsi自增1
ror r8d,0dh ; 对当前哈希值(r8d)循环右移13位
add r8d,eax ; 将当前字符的ASCII值(al)累加到哈希值(r8d)
cmp al, ah ; 检测当前字符是否为0(字符串结束符)
jne loop_funcname ; 若字符非0,继续循环处理下一个字符
add r8,[rsp+8] ; 将之前压栈的模块哈希值加到当前函数哈希
cmp r8d,r10d ; r10存储目标hash
jnz get_next_func ;获取下一个函数没什么好说的,同32位一致。
(8)第八步:获取目标函数指针
pop rax ; 从栈中获取之前存的导出表地址
mov r9d, dword ptr [rax+24h] ; 获取序号表的RVA
add r9, rdx ;RVA转VA:序号表起始地址
mov cx, [r9+2*rcx] ; 从序号表中获取目标函数的导出索引
mov r9d, dword ptr [rax+1ch] ; 获取函数地址表的RVA
add r9, rdx ;RVA转VA:AddressOfFunctions数组的首地址
mov eax, dword ptr [r9+4*rcx] ; 获取目标函数指针的RVA,每个目标函数指针占4个字节
add rax, rdx ;RVA转VA:获取目标函数指针的地址还是一系列的RVA与VA的转换操作,这里不多说了。
(9)第九步:清理栈及收尾工作,调用目标函数
finish:
pop r8 ; 清除当前模块hash
pop r8 ; 清除当前链表的位置
pop rsi ; 恢复rsi
pop rcx ; 恢复第1个参数
pop rdx ; 恢复第2个参数
pop r8 ; 恢复第3个参数
pop r9 ; 恢复第4个参数
pop r10 ; 将返回地址存储到r10中
sub rsp, 20h ; 给前4个参数预留 4*8=32(20h)的影子空间
push r10 ; 返回地址
jmp rax ; 调用目标函数将之前压栈的寄存器弹出来,恢复寄存器的值。这里涉及到一个概念:影子空间。它是一块位于被调用函数堆栈帧顶部的保留内存区域。
Windows x64 ABI 规定:调用函数在执行call指令进入被调用函数(子程序)之前,必须在堆栈上预留出 32 个字节(刚好能容纳4个QWORD/64位指针)的未初始化空间,这块空间就是影子空间,主要用于保存寄存器参数,所以这块影子空间需要被清除掉。
4.2 main函数
; 第一步:调用cld指令清除方向标志,将栈指针对齐到16字节边界
cld ; 清除方向标志,标志位DF=0
and rsp, 0FFFFFFFFFFFFFFF0h ; 栈指针16字节对齐,X64调用约定的强制要求
; 第二步:user32字符串和目标hash压栈,加载user32.dll库
push 0 ; 对齐
mov r14,0000323372657375h ; "user32\0"
push r14 ; 字符串压栈,此时rsp指向"user32\0"字符串
mov rcx,rsp ; rcx=字符串指针
mov r10,0DEC21CCDh ; 计算kernel32.dll+LoadLibraryA的hash值
call get_func_address ; 调用哈希解析函数获取LoadLibraryA地址,加载user32.dll
; 第三步:调用MessageBoxA函数弹窗
push 0 ; 对齐
mov r14,006f6c6c6568h ; "hello\0"
push r14 ; 将字符串压栈,此时rsp指向"hello\0"字符串
xor rcx,rcx ; hWnd=NULL
mov rdx,rsp ; lpText=hello\0
xor r8,r8 ; lpCaption=NULL
xor r9,r9 ; uType=0
mov r10,790E24F0h ; 计算user32.dll+MessageBoxA的hash值
call get_func_address ; 执行MessageBoxA函数
; 4.调用ExitProcess,退出
xor rcx,rcx
mov r10,2E3E5B71h ; 计算kernel32.dll+ExitProcess函数的hash值
call get_func_address ; 执行ExitProcess函数关键指令解析
- and rsp, 0FFFFFFFFFFFFFFF0h:该指令用于将栈指针对齐到16字节的边界,这是Windows X64调用约定强制要求的规范;
- push 0:该指令用于使rsp对齐;
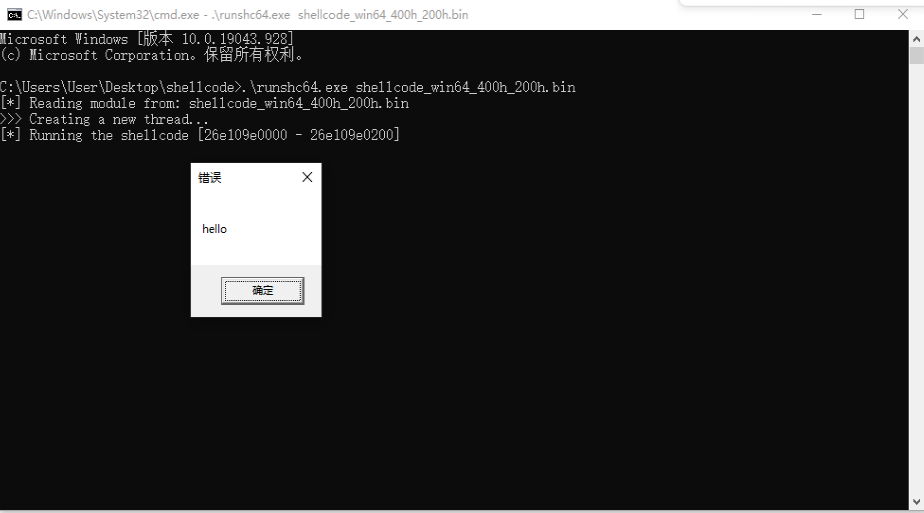
4.3 运行测试
运行测试的过程同32位一致,生成方式选择X64位即可,直接看下效果:
5. 参考链接
- msf-shellcode-win-x86:https://github.com/rapid7/metasploit-framework/blob/master/external/source/shellcode/windows/x86/src/block/block_api.asm
- msf-shellcode-win-x64:https://github.com/rapid7/metasploit-framework/blob/master/external/source/shellcode/windows/x64/src/block/block_api.asm
- x86 Assembly Guide:https://www.cs.virginia.edu/~evans/cs216/guides/x86.html
- Windows shellcode 开发入门 – 第三部分:https://securitycafe.ro/2016/02/15/introduction-to-windows-shellcode-development-part-3/
- Windows Shellcode开发:https://xz.aliyun.com/news/17644
- Windows Shellcode开发(x64 stager):https://xz.aliyun.com/news/17961
1. 一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
